Why this build
I wanted deep, hands-on experience engineering with AI agents — so I picked a use case that’s real, widely felt, and instantly recognizable: the modern job search. It exercises everything that matters in agent products (multi-step pipelines, model economics, deterministic guardrails, a human firmly in the loop), and the result is genuinely useful to people in an active search — which is why it’s open source.
The product
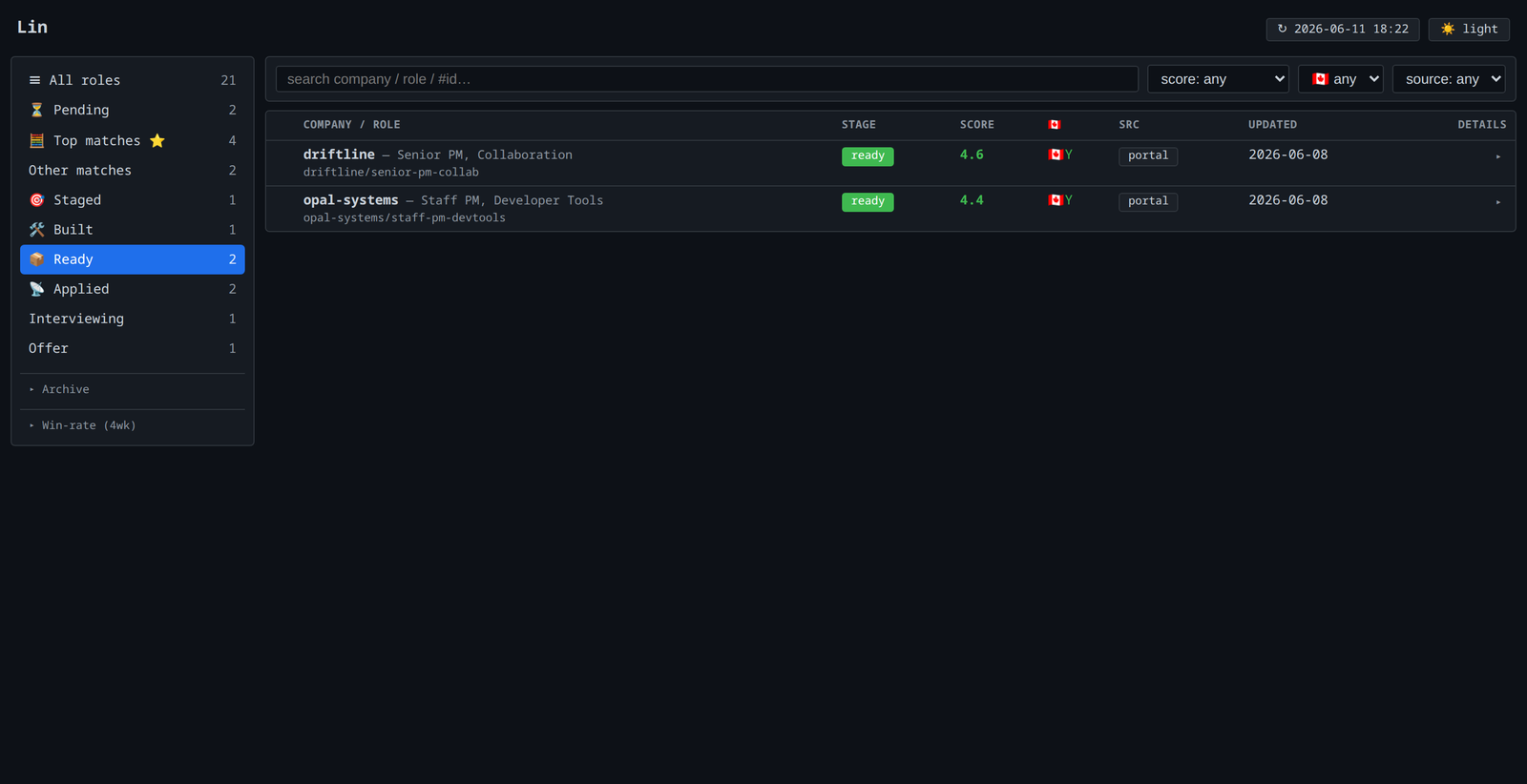
A job search is an operations problem run at emotional expense. Lin automates the operations: it scans portals twice daily, scores every role with a structured 0–5 evaluation plus a configurable geo-eligibility gate, verifies a posting is still live, builds two competing tailored résumés — one engine optimizes narrative for humans, the other injects keywords for ATS robots — picks the winner by automated comparison, drafts the application answers, and tracks every application with inbox-driven status updates and an engine win-rate scoreboard.
One product rule never bent: the user always submits. Lin prepares everything; it never applies for anyone.
🎭 Click through the live demo (fictional data) · 💻 Source on GitHub
V1: speed, then the receipt
V1 shipped the way scrappy products ship — the next most valuable thing every few days, over roughly two weeks, on top of two résumé engines that represented months of prior customization work. It worked: in live validation, 300+ real postings evaluated and ~70 carried end-to-end into complete application packages, with the résumé engines A/B-tested on every package produced. The rig even included a daily cost-report job and a controlled model A/B test — the same roles run through the expensive default and two cheaper models to find out what résumé quality actually required. But every iteration left a layer behind: workflow logic drifted into scheduler prompts (three hand-synchronized copies), the agent’s instruction set grew into a single 750-line monolith loaded into every run, and the most expensive model spent its budget browsing web pages before rate-limiting out of the work it was actually for. Functional daily — but accumulated, not designed.
V2: a real product process, run with an AI agent
I rebuilt it without stopping it — and my entire engineering team was one AI agent. My role stayed purely product:
- Vision, not spec. One page of principles, plus the instruction that shaped everything: “do an independent analysis — existing docs are reference only.” The audit caught the docs lying.
- Decisions at gates. Three architecture options → four multiple-choice decisions → everything downstream traced to them.
- AI reviewing AI. A second frontier model returned 16 design amendments; the agent fact-checked each against the codebase — 14 held, including a genuine data-integrity bug.
- Data over opinion. My own approved auto-build threshold would have built nothing against the real score distribution. The numbers won; the rule changed.
- Prototyping in the browser. Layouts, table anatomy, interaction model and visual style chosen from clickable mockups rendered with real pipeline data from the running system — twenty minutes of design decisions.
- Cutover with rollback. Contracts-first migration, dry-run manifest, invariant checks, stage-by-stage switchover. On night one, the new pipeline autonomously carried a real posting from discovery to a quality-gated, submit-ready package — production as the acceptance test.
The PM craft on display
- Model A/B testing. Identical roles were run through the premium model and two cheaper ones via real scheduled jobs, judged on next-stage usefulness rather than style. The surprise: a budget model produced richer drafts (with validators required) — evidence that reshaped the architecture.
- Cost analysis → model tiering. A daily cost-report job priced every API call per pipeline stage. It exposed a deterministic tracker burning 60+ LLM calls/day (now zero-LLM code) and the premium model rate-limiting on browsing before reaching résumé work. Result: cheap models for routine stages, one frontier job reserved for the writing that is the product — routine operations now cost cents per day.
- Automation vs human-in-the-loop. Autonomy is graduated, not binary: discovery/scoring/tracking run fully automatic; expensive builds auto-trigger only for the top-3 daily roles above a data-derived threshold; everything else is one human click; submitting and any outbound email are human-only, by hard rule. The thresholds came from the data, not intuition.
- Prototyping. Dashboard layout, table anatomy, interactions and visual style were chosen from clickable in-browser mockups rendered with live pipeline data — minutes per decision, no design tool.
- Iterative development with review gates. Plans as written docs, adversarial review by a second AI model (then fact-checking the reviewer), platform behavior probed with throwaway experiments before implementation, and a contracts-first, zero-downtime migration with instant rollback.
Outcome
| V1 | V2 | |
|---|---|---|
| Scheduled jobs | 15, with multi-page prompts | 10, prompts ≤ 2 lines |
| Workflow home | scattered prompts + one 750-line monolith | 11 small, single-purpose skills |
| Context overhead per run | ~21k tokens | ~2k tokens (−90%) |
| Premium-model exposure | 3 jobs (incl. web browsing) | 1 job — résumé writing only, top-N gated (~3× less volume) |
| LLM calls on budget models | mixed, unmeasured | ≈95% (telemetry-verified) |
| Routine pipeline cost | unmeasured | ~$0.30/day |
| Postings → packages | 300+ evaluated, ~70 completed end-to-end | same throughput, uninterrupted |
| Automated tests | 0 | 60 (incl. real-browser click-through) |
| Downtime during rebuild | — | none |
The full system is open-sourced as a reusable Hermes skill suite — sanitized to a placeholder profile, with the résumé engines’ MIT upstream projects fully credited — alongside the live demo dashboard (funnel-rail navigation, sortable table, bulk actions, dark/light personalities).
Deep-dive case studies: V1’s iterative build and the V2 rebuild playbook are available as a two-part write-up — and the open-source repo’s README doubles as the architecture tour.